聚焦产品:数字空间里的数据如何被挖掘,又可以应用在哪里
围绕物品识别和文本识别这两个大类,聚焦解读如视的空间数据挖掘能力。
聚焦产品
从「数字空间高效精准搭建」——1:1完整复刻、15分钟完成百平空间采集,到「空间深度信息多元挖掘」——真实还原线下空间信息、叠加多样化延展应用,如视「软硬一体的数字空间解决方案」背后的支撑力是什么?【聚焦产品】栏目带您深入解读如视产品能力。
在上期聚焦产品栏目中(聚焦产品 | 如视的三维重建为何快速且真实?图像处理能力给出一些答案),我们详细介绍了如视的图像处理能力,并且了解到这个能力如何帮助如视的三维重建快速且真实。而今天,我们则将围绕物品识别和文本识别这两个大类,聚焦解读如视的空间数据挖掘能力。
如视深耕于三维重建领域,通过采集真实的空间深度信息,获得物体的几何结构,再结合RGB相机采集的图像信息、算法融合之后得到真实空间三维重建结果。
三维重建背后的空间全量数据和深度信息,是如视得天独厚的优势。那么,如何挖掘和广泛应用这些数据和信息,是至关重要的问题。
接下来,就与我们共同走进空间数据挖掘这一能力,去看一看空间数据挖掘能力具体指什么?它是如何实现的?以及如何利用这一能力实现空间的数字化、智能化应用。
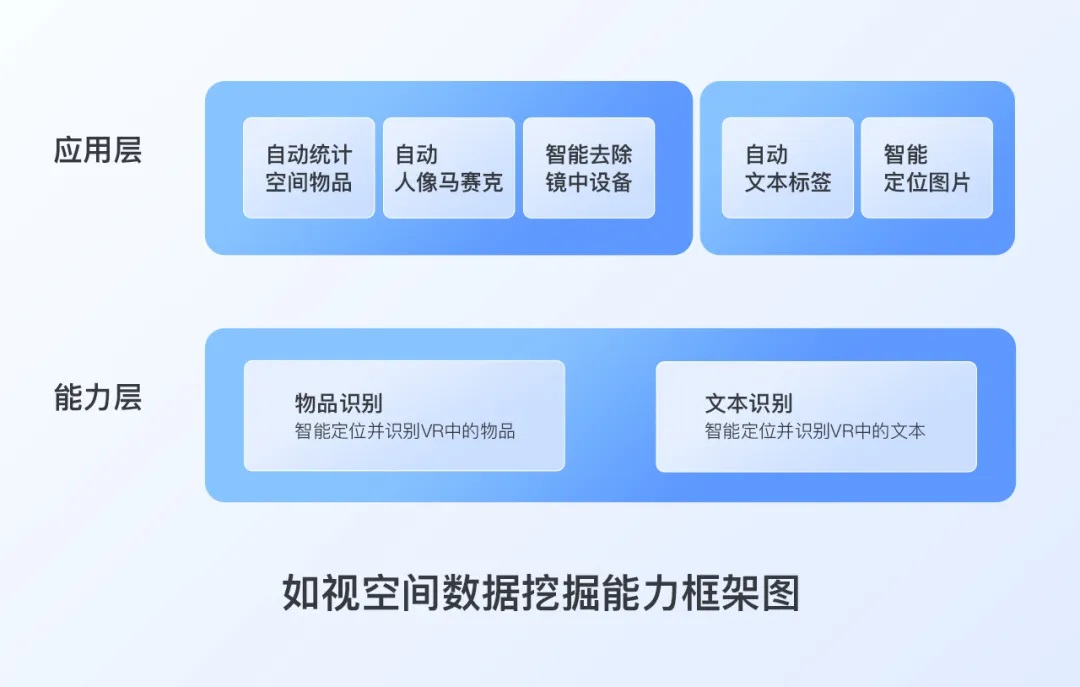
01 物品识别
走近物品识别
谈到空间数据挖掘能力,首先是物品识别。
在三维空间中,有人有物,人眼能够轻松分辨出桌椅和沙发、房间中有几个人、冰箱和洗衣机有什么区别,物品识别能力即是让计算机也能像人一样完成上面这些识别。
如视针对于物品识别能力,做了大量的研究和训练。能够识别出住宅场景中的大多数物品,高效输出数字空间中的物品列表、每个物品在空间中的具体位置、物品的最佳观测点位和视角,以及物品自动截图和轮廓等。
目前,如视物品识别已经覆盖了日常生活空间中常见的百余类物品,包括家具、家电、门窗等。此外,如视还能针对空间中的人体、人像进行精准识别,满足用户在三维重建空间中的多样化应用场景需求。

精准识别能力背后,离不开如视深耕三维重建行业多年积累下的海量真实空间数据。
作为全球最大的三维空间数据库拥有者,截止到2024年6月,如视的数字空间采集量突破4000万,总采集面积已达到33.2亿平方米。因此,如视能够为计算机提供海量的样本集进行算法训练,让AI算法足够“见多识广”,赋能其物体识别能力。
基于物品能力,如视得以实现空间的数字化、智能化应用,为用户提供更丰富、更便捷、更先进的服务。
物品识别的数智化应用场景
减少物业交割纠纷
据贝壳统计,房地产行业买卖签后,客诉率最高、最严峻的问题就是物业交割问题。
和产权、交割时间、支付方式这些重要事项不同,一个易被忽视,却经常产生纠纷的交割项是室内重要物品的交割。
比如,买卖双方口头约定,房屋内所有高档家具均包含在房屋总价中。出于信任,买方并没有仔细核对合同中的物品明细。而到了物业交割时买方才发现,所有高档家具早已被替换为劣质品。
如视提供的物品识别能力及时充当了“证人”的角色。在交房环节,如视能够将识别到的室内物品自动截图,并带入物业交割清单,增加签后复核环节,确保在交易现场就能够实时且全面的完成物业交割。同时,由于不需要人工参与进行物品交割,能够大幅度降低人力成本。
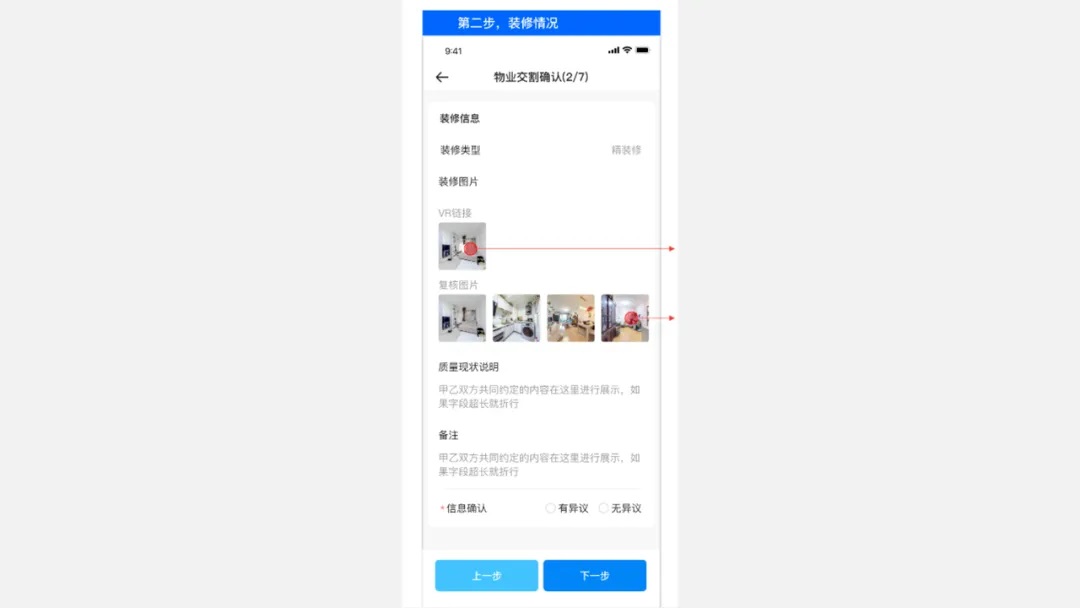
同人工统计相比,如视的物品识别功能效率高、不易遗漏,能够在一定程度上降低买卖双方的物业交割纠纷,用科技为用户带来更优质的服务体验。
辅助收房定价+丰富房源信息
租房中介平台收房时,影响收房价格的主要有几个因素,包括:房源位置、类型、房屋面积、以及房屋物品信息等。而这其中较难统计的,就是房源中的物品信息,比如是否有采暖设备、是否支持燃气做饭等。
过去,收房管家进行这项工作时,主要通过人工来做整屋记录,不仅消耗时间长、效率低,并且不可避免的会产生遗漏、错记等问题,影响房源价值。
如今,管家可以应用如视的物品识别能力,辅助租赁房屋定价。如视能够自动汇总三维空间内重点物品的数量,辅助收房管家高效、准确的完成物品记录工作。在帮助企业提高人效的同时,也让收房定价更加有理有据,从而给到业主、租客一个客观、合理的价格。
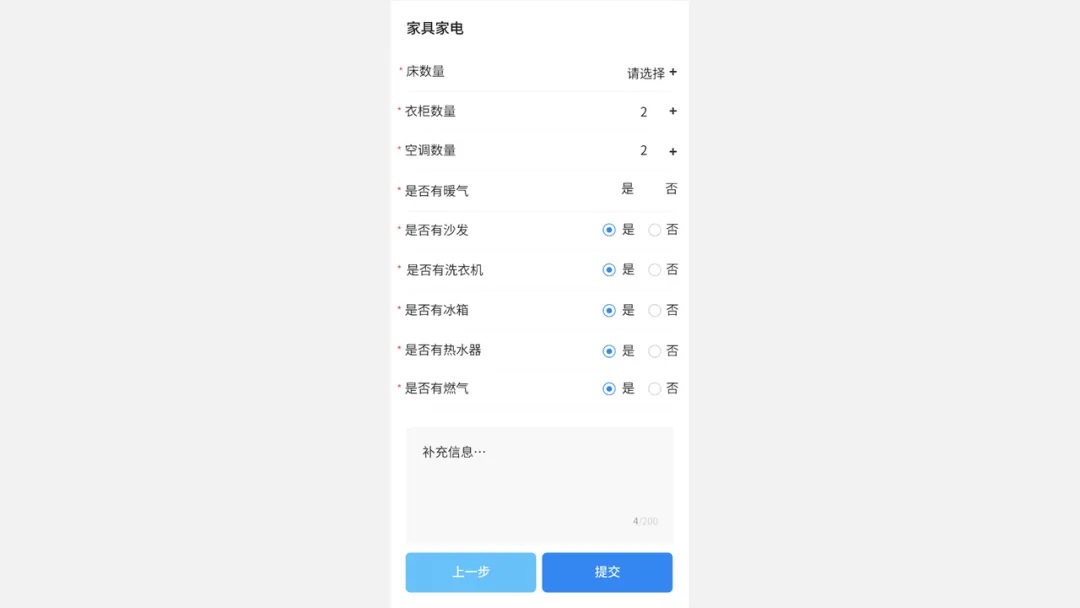
在租赁房源搜索端,用户的需求也愈发精细化,比如想租赁一间附带大衣柜的房屋,就会搜索关键词“衣柜”。所以,很多租房平台希望为每一套房源都建立全面的信息记录档案,丰富房源的数据维度,便于用户或客户经理根据物品分类情况进行搜索找房。
而人工亲临房屋内或在VR中逐件记录物品的效率很低,且难以保证实时性。利用如视的物品识别能力,能够全自动识别出房源中的常见物品,并自动生成信息标签,为搜索端数据库提供了全面、可靠、具备时效性的房源信息。

镜中设备一键去除:真实空间完美映照
当用户在浏览数字空间时,如果忽然发现镜中伫立着一台拍摄仪器,会很大程度上影响用户的真实体验。
一直致力于为用户提供沉浸式漫游体验的如视,自然不会放过这些“穿帮镜头”。通过物品识别能力,如视能够自动识别出镜像中的采集设备,并利用图像填充技术进行智能填充消除,让镜中世界同样映照出“真实空间”。
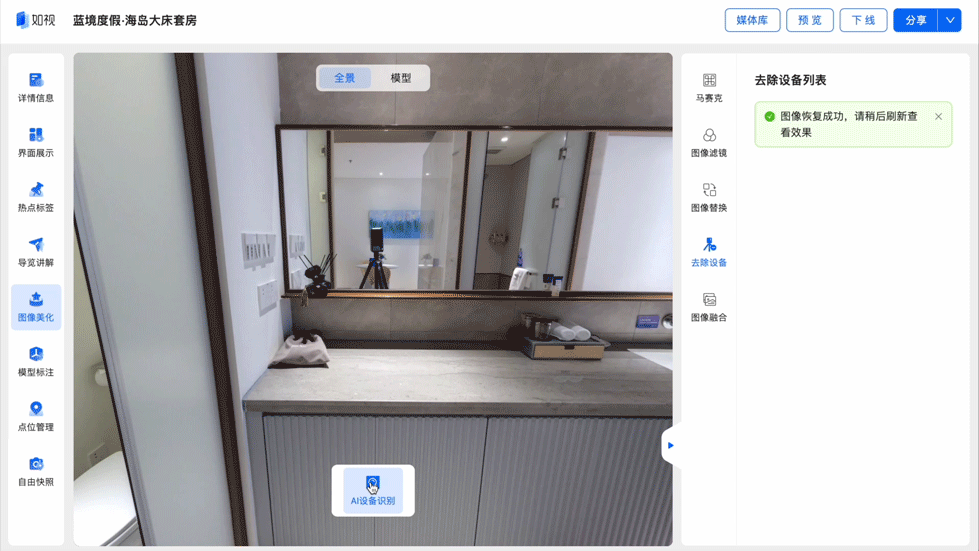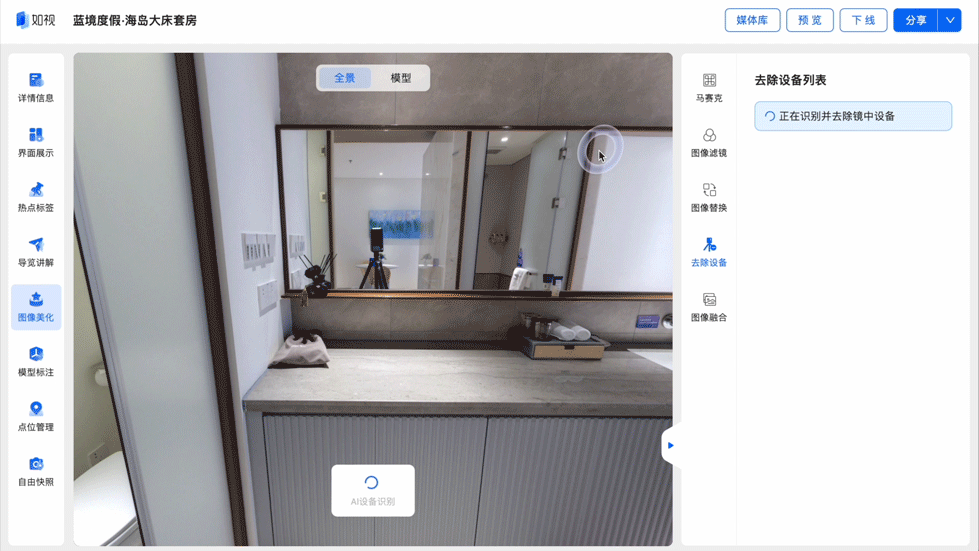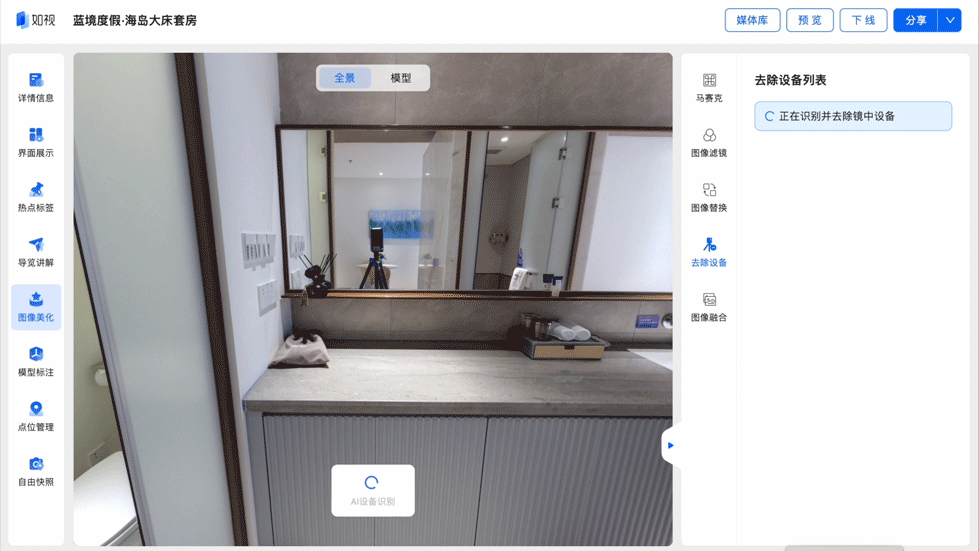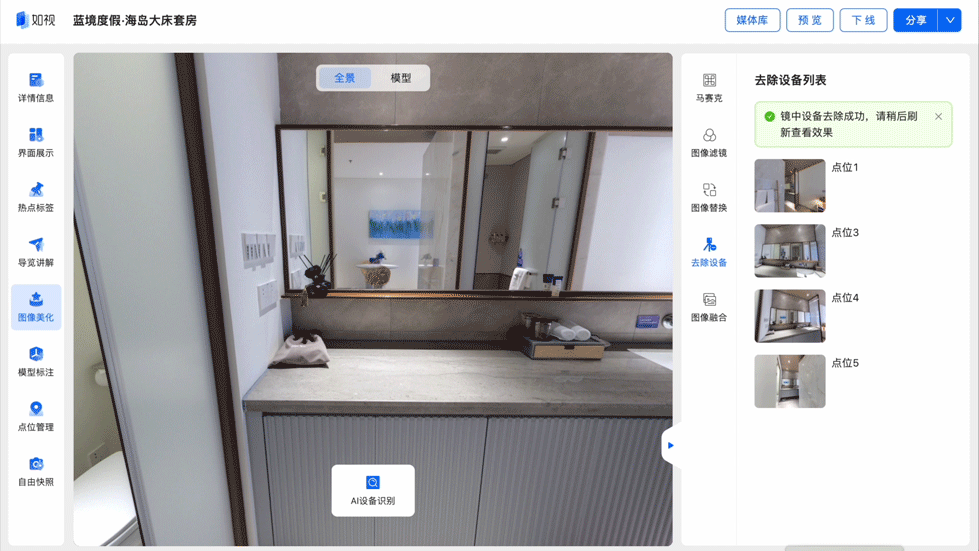
人像识别:注重隐私更合规
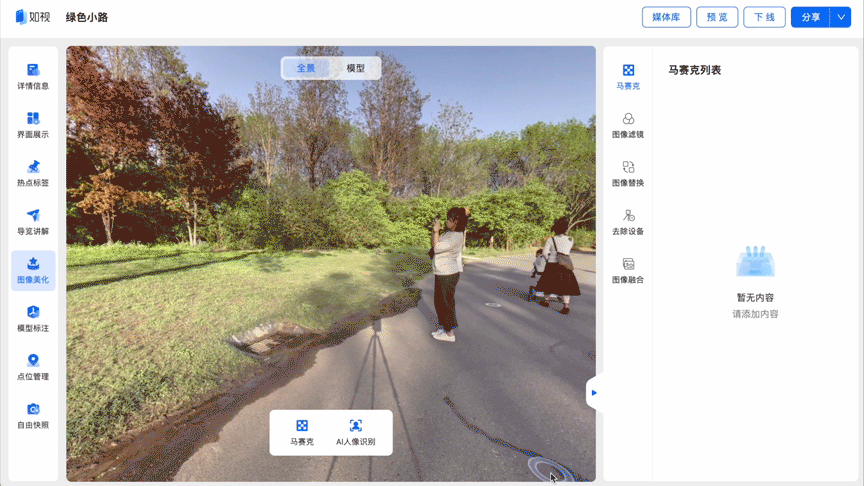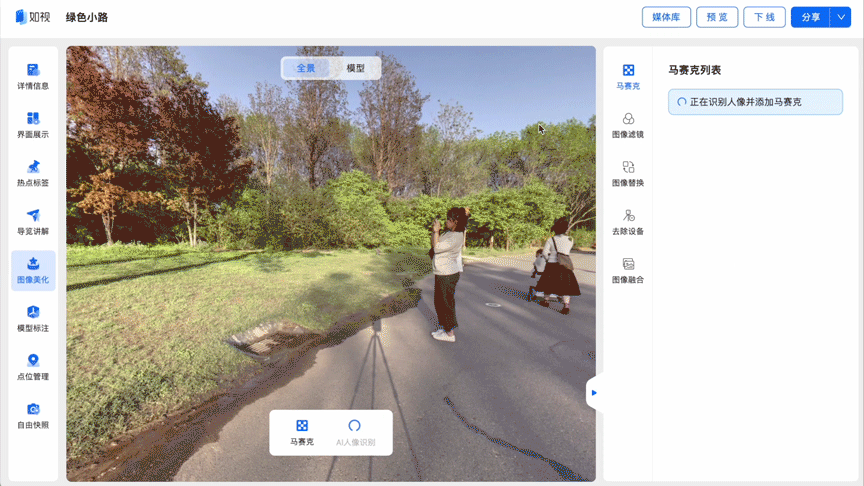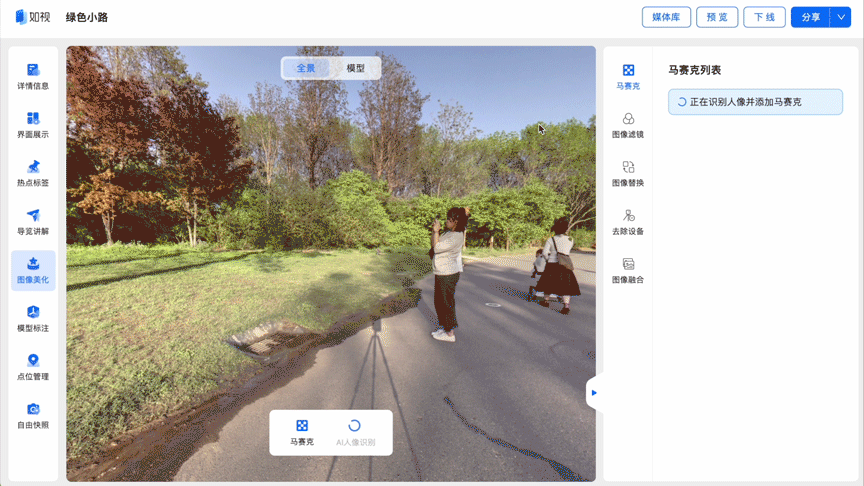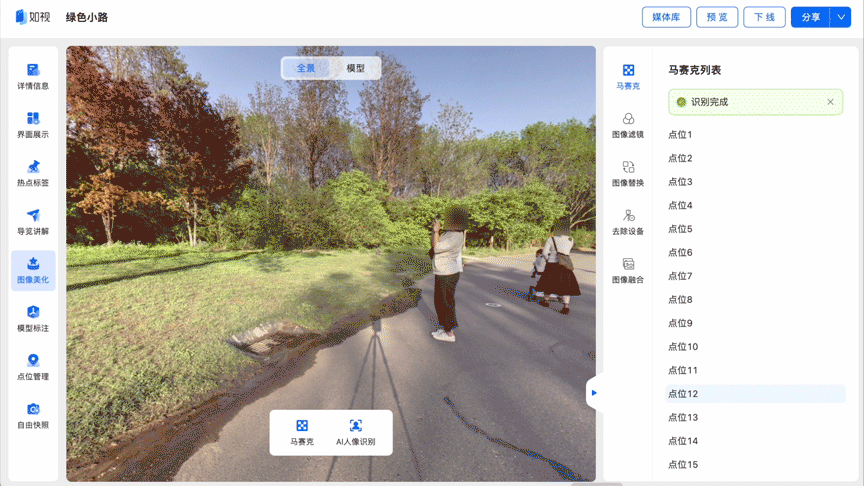
在针对部分物理空间,如展厅、景区等进行数字空间采集时,不可避免的会采集到人像。如果想要让内容合规发布,并保护个人隐私,就需要对数字空间中的人像进行马赛克处理。
如果数字空间中存在大量人像,逐个进行手动打码不仅费时费力,还容易遗漏。利用如视的数字空间人像识别技术,能够精准识别出VR图像中的人像区域,并对其在图像中的具体位置进行标注,自动进行马赛克处理,极大节省了手动“打码”的时间,提高了用户体验。
02 文本识别
什么是文本识别
空间数据挖掘能力中的文本识别,也同样具有重要意义。
在三维空间中,除了物品外,还会存在大量文本信息。而文本信息对于用户来说同样具有极高价值,对于文本的识别和提取同样可以赋能诸多应用。比如工业场景中设备的标牌、展览中展品的文本介绍等。
传统文本识别采用OCR技术,又叫光学字符识别技术。其原理是先识别出图像或扫描文档中的文字,再将其转换为可编辑的文本格式。
传统OCR识别仅适用于图像文本清晰可见的情况。而在数字空间场景中,经常会出现非常小且十分模糊的文字,采用传统OCR很难检测出全部文本,即使针对已检测出的区域,识别错误率也较高。
针对这个问题,如视开发了传统OCR识别的“Pro Max”版本——如视文本识别。
不但能够识别出数字空间中的文本内容(支持中、英、数字、符号),还能够输出每个文本的三维位置和最佳观测视角,对于细小模糊的文字,也能够做到精准识别。

那么,如视是如何将传统OCR升级成“Pro Max”版本的呢?
- 首先,通过检测算法找出空间中所有的文本区域;
- 其次,根据深度信息对检测出来的文本区域进行定位和聚合;
- 最后,对文本区域进行多倍率的识别,精准识别出图像中的文本,让模糊和微小的文本也不会被遗漏。
基于精准的文本识别能力,如视得以创造更多在数字空间中的数智化应用。
文本识别如何赋能行业应用
工业场景应用:自动定位标牌,提高生产效率
在工业场景中,车间地图复杂、设备数量多。如果某样设备突发故障报警,在没有获悉设备准确定位的前提下,维修人员往往会因此耽误维修时间,对生产造成一定影响;而如果用人工进行打标记录,则会花费较大的时间和人力成本。
利用如视数字空间文本识别功能,能够识别设备的标牌信息并自动生成标签,节约了人工打标签的成本,并且能够在设备报警时,辅助工作人员快速定位故障设备并启动维修。

刑侦场景应用:物证照片精准定位
在刑侦场景中,每丝毛发,每片纸屑都可能作为关键物证存在。案发后,鉴识人员首先要对物证拍照留存,并打上相应标签。
而后期调查人员在调查时,往往需要通过获悉每个物证在案发现场所处的具体位置,来进一步分析案情,比如血液滴溅位置、脚印方向等。这时采取人工方法进行一一对应,不但繁复,还要谨慎小心、避免出错。
利用如视的图片定位+文本识别能力,当用户上传案发现场细节照片时,系统会自动识别照片上的物证编号,并且和数字空间中文本识别的结果匹配,让相应物证编号的图片直接匹配到数字空间中的对应位置,极大提高了调查人员的工作效率。

文博会展场景:框选自动识别,高效信息管理
在数字空间中,除如视提供的自动打标签能力外,部分用户还需要从数字空间中提取一些特殊文本信息并对其添加标签。
比如在文博会展场景中,面对数字空间里的数百幅画作,用户需要单独为每一幅画作添加背景信息,如作品名称、作品介绍等。如果没有文字识别能力,用户只能手动输入冗长的文字作为标签。
基于此,如视可以为用户提供框选自动识别功能。在数字空间中,用户只需任意框选一个区域,系统即可识别其中的文本信息,自动复制到粘贴板,方便用户使用。

利用文本识别能力,不仅简化了用户提取文本的操作流程,还极大提高了标签添加的效率,使复杂的数字空间环境中的信息管理变得更加轻松、高效。
想要实现空间的数字化和智能化转型,离不开如视对技术力的追求、对空间数据的挖掘、和对行业应用场景的深刻理解。
如视依托其海量数据库训练的算法和在行业内钻研数载的宝贵经验,不断打磨自身空间数据挖掘能力,未来会不断延伸空间数据挖掘的广度以及加深空间数据挖掘的深度,并将这一能力更好地赋能空间的数字化和智能化应用,为各行各业提供更丰富、更便捷的服务。
本期聚焦产品栏目到这里就结束了,如果想了解更多的如视产品“秘籍”,欢迎大家在评论区留言,我们下期见。


