EDM: Efficient Deep Feature Matching
Abstract
Recent feature matching methods have achieved remarkable performance but lack efficiency consideration. In this paper, we revisit the mainstream detector-free matching pipeline and improve all its stages considering both accuracy and efficiency. We propose an Efficient Deep feature Matching network, EDM. We first adopt a deeper CNN with fewer dimensions to extract multi-level features. Then we present a Correlation Injection Module that conducts feature transformation on high-level deep features, and progressively injects feature correlations from global to local for efficient multi-scale feature aggregation, improving both speed and performance. In the refinement stage, a novel lightweight bidirectional axis-based regression head is designed to directly predict subpixel-level correspondences from latent features, avoiding the significant computational cost of explicitly locating keypoints on high-resolution local feature heatmaps. Moreover, effective selection strategies are introduced to enhance matching accuracy. Extensive experiments show that our EDM achieves competitive matching accuracy on various benchmarks and exhibits excellent efficiency, offering valuable best practices for real-world applications.
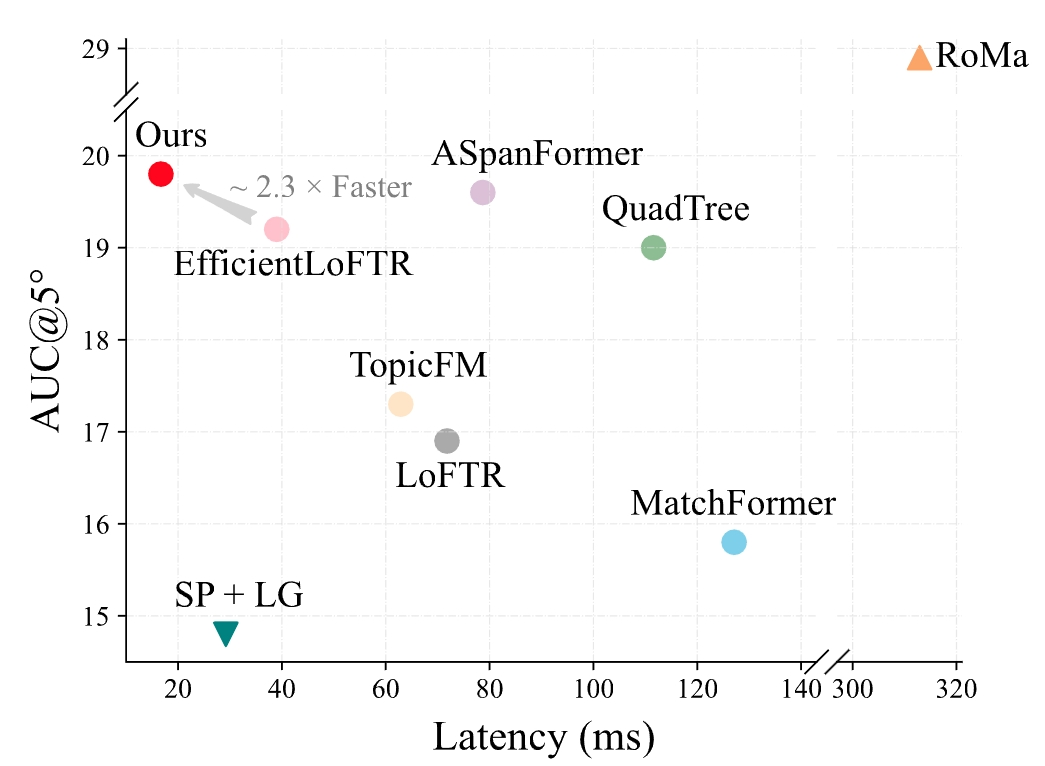
Figure 1. Comparison of Matching Accuracy and Latency. Our method achieves competitive accuracy with lower latency. Models are evaluated on the ScanNet dataset to get AUC@5◦ accuracy, while the latency for an image pair with 640×480 resolution is measured on a single NVIDIA 3090 GPU.
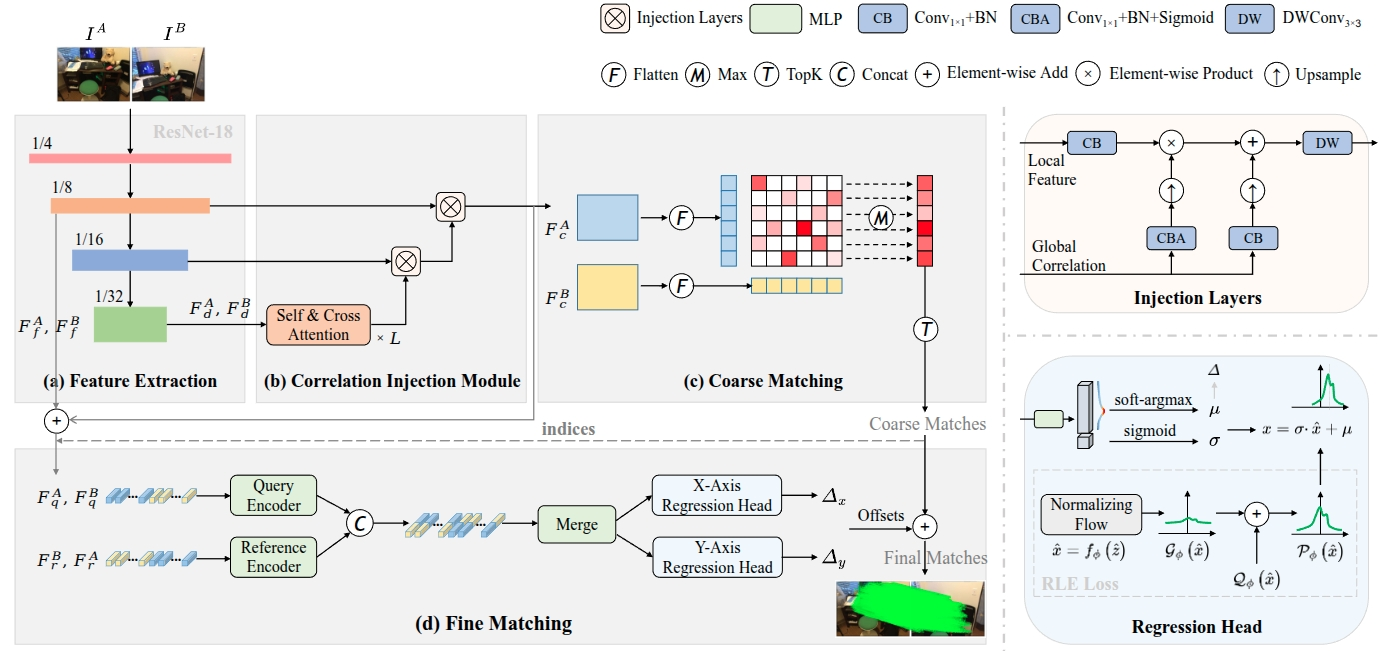
Figure 2. Pipeline Overview. (a) A deeper CNN backbone is adopted to extract multi-level feature maps. (b) In the Correlation Injection Module, we alternately apply self-attention and cross-attention a total of L times to capture and transform the correlations between deep feature FA_d and FB_d. Subsequently, two Injection Layers are employed to progressively inject feature correlations from deep to local levels.(c) After the CIM, the coarse features FA_c and FB_c are flattened and then correlated to produce the similarity matrix. To establish coarse matches, we determine the row-wise maxima in the probability matrix and select the top K values among them. (d) For fine-level matching, the corresponding fine features are extracted by the indices obtained from the coarse matching process. We treat the fine features FA_q and FB_q as queries, while considering the same features but in reversed order, FB_r and FA_r, as eferences. The query and reference features are encoded separately and then merged together. Then, a lightweight regression head is designed to estimate the reference offsets on the X and Y axes, respectively. The final matches are obtained by adding the coarse matches to their corresponding offsets.

Figure 3. Bidirectional Refinement. For a coarse matching pair, the center point of one grid serves as query for fine matching, and its corresponding reference point is offset from the center point in another grid, exhibiting duality.
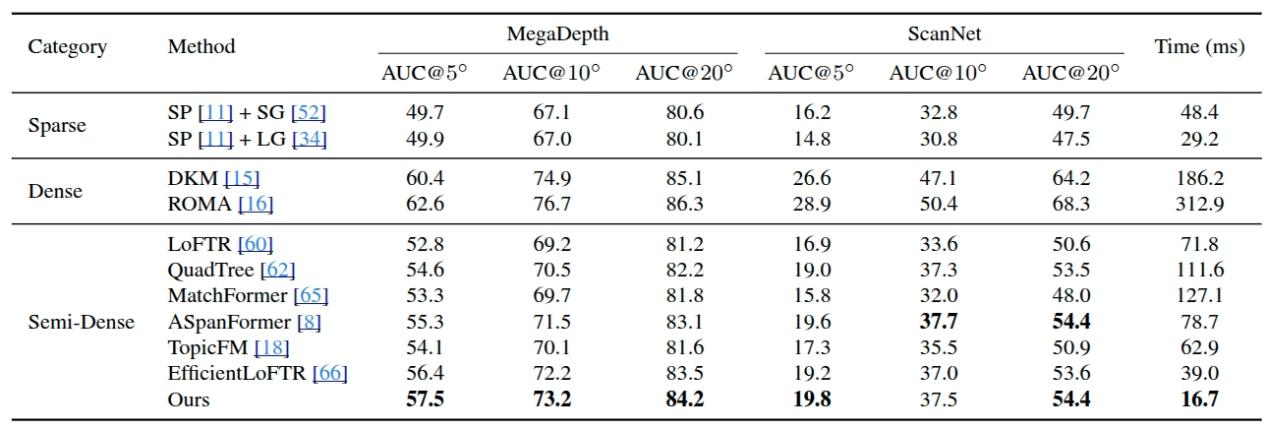
Table 1. Results of Relative Pose Estimation on the MegaDepth Dataset and ScanNet Dataset. The models are trained on the MegaDepth dataset to evaluate all methods on both datasets. The AUC of relative pose error at multiple thresholds, and the average inference time on the ScanNet dataset for pairwise image of 640×480 resolution is provided
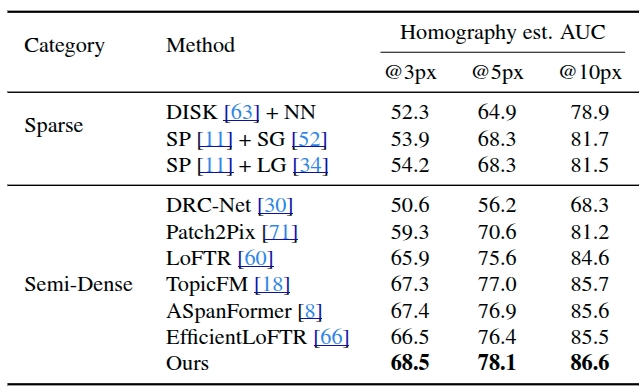
.Table 2. Homography estimation on HPatches.
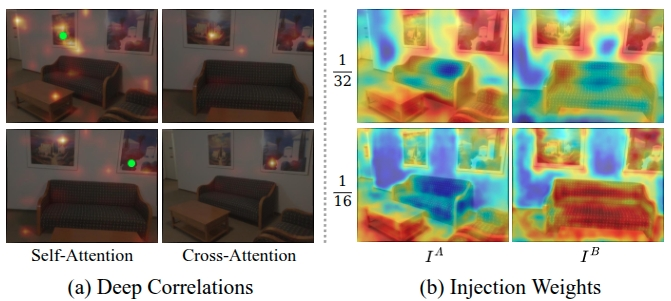
Figure 4. Attention Visualization. (a) Deep correlations. The green dots represent the query points. (b) Injection weights. Significant response values usually located in detail-rich regions.
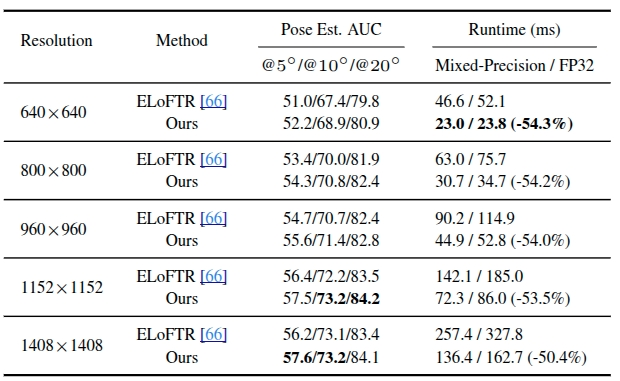
Table 3. Comparison of image size on the MegaDepth dataset.
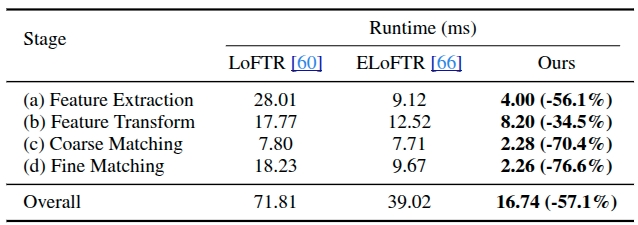
Table 4. Runtime comparisons for each stage on ScanNet dataset.

Figure 5. Qualitative Comparisons. Compared with LoFTR and EfficientLoFTR, our method is more robust in scenarios with large viewpoint changes and repetitive semantics. The red color indicates epipolar error beyond 5e-4 in the normalized image coordinates.
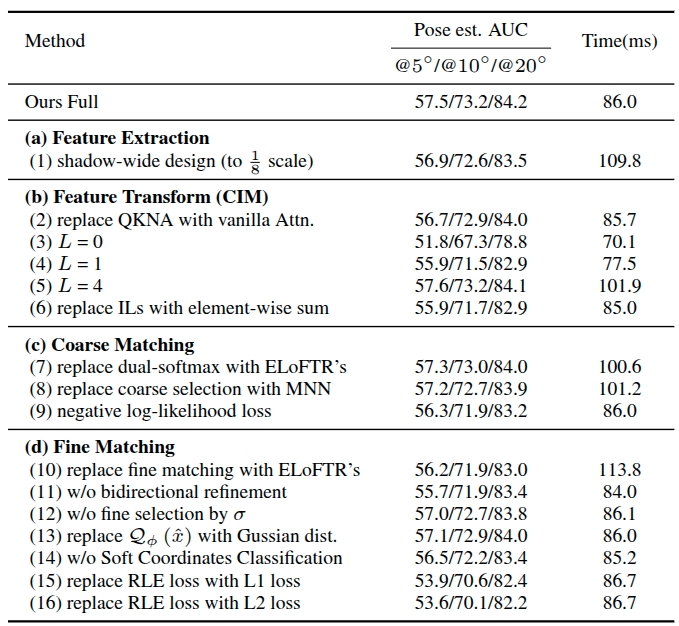
Table 5. Ablation studies on the MegaDepth dataset at all steps, with average running times measured at 1152×1152 resolution.


