李飞飞押注、CVPR 2026获大奖!空间智能爆发,这家中国公司正在打造3D世界的“GPT接口”!
Argus 1.0 Skill已上架多个大模型平台
当下,世界模型(World Model)已成为 AI 行业最火热的赛道之一。视频生成在全面转向通往物理 AI 的世界模型;具身智能中的 VLA 顶流地位不保,逐渐被世界动作模型(World Action Model)占据。但关于什么是世界模型,大家还没有达成共识。
AI 科学家李飞飞在 6 月 4 日发布长文,对世界模型的定义和发展方向进行了系统性阐述。她将世界模型划分为渲染器(Renderer)、模拟器(Simulator)、规划器(Planner)三大功能形态,并称:模拟器是实现 AI 融入真实物理世界的核心关键,领域内最困难的未解问题也都集中在模拟器。6 月 13 日,李飞飞联合创立的 World Labs 更是一次性发布了三篇突破性论文,全部聚焦于 3D 生成、4D 生成任务。
无独有偶,刚刚落幕的 CVPR 2026 国际计算机视觉顶级会议上,3D 重建、3D 生成、空间建模相关研究包揽最佳论文、最佳学生论文等重磅奖项。学术圈与工业界形成共识:想要做强模拟器类的世界模型、落地物理 AI 与具身智能,真实场景三维数字化技术是无法绕开的底层底座。
而在国内,一家深耕空间数字化十余年的公司,已经提前布局这场变革,它就是——如视科技(Realsee)。如视基于空间大模型 Argus 1.0 推出的 Argus 1.0 Skill 已支持 Claude Code、Codex 等多个大模型平台,也让更多开发者开始关注这个长期低调的空间智能玩家。
从图像到 3D:Argus 1.0 补齐世界模型短板
在过去很长一段时间里,3D 重建一直是计算机视觉领域最困难的问题之一。传统方案通常需要:多视角采集、大量特征匹配、复杂几何优化、漫长计算时间,整个流程不仅复杂,而且对数据质量要求极高。而 Argus 1.0 试图改变这一切。
如视推出的空间大模型 Argus 1.0 最大的特点在于:支持全景图输入,实现单张或多张全景图到 3D 空间的毫秒级转换,可以推理出所有图像带绝对尺度的相机位姿、深度图和点图。

Argus 1.0 技术原理
- 首创全景图输入:业界首个支持全景图输入的深度推测大模型,能兼容单张或多张照片及 AI 生成的图片。
- Transformer 架构:基于 Transformer 构建的前馈式神经网络模型,显著提升模型的性能,实现高精度的空间重建。
- 大规模真实数据训练:覆盖多种场景,确保模型生成的三维空间具有高可靠性、高泛化性。
- 毫秒级实时重建:通过优化算法和架构设计,快速响应输入,提供无感知的用户体验。
Argus 1.0 Skill 上线
从 TensorFlow 到 PyTorch,从 GPT、Claude Code API 到各种 Agent 工具链,每一次技术革命真正爆发的标志,都是能力被标准化调用。而 Argus 1.0 Skill 正在做的事情,本质上也是如此。它让空间智能从一个复杂研究课题,变成一种可调用的基础能力。换句话说:如视正在尝试把空间能力做成“API化的空间操作系统”。
Argus Skill 的核心能力:空间深度估计、相机位姿估计等,可以应用于空间拼接 、多视角对齐 、VR 空间生成 、数字孪生等,而且可以应用于水电纪录、临展纪录、餐厅展示等生活化场景。未来还将开放:空间 CAD 自动生成、空间物体检测与分割、空间语义识别、空间编辑与再加工、漫游视频生成。
Argus 1.0 Skill(体验版)已经发布到 github 上,强烈推荐大家试玩:
https://github.com/realsee-developer/skills

为什么 Argus 1.0 能领先?空间数据是核心护城河
AI 行业有一句老话:模型决定上限,数据决定下限。放在空间智能领域,这句话甚至还不够准确。因为很多时候:数据既决定上限,也决定下限。
空间智能最大的挑战,不是模型框架,而是真实世界。因为现实空间远比图片复杂,不同房型,不同装修,不同设备,不同光照,不同遮挡,甚至同一个房间,在不同时间拍摄都会出现巨大差异。当前很多公司、实验室依赖合成数据、小规模场景、单一采集设备所训练出来的3D模型可以在特定环境下表现优异,但是一旦进入真实世界,效果往往大打折扣。而这恰恰是如视最大的优势所在。
如视十年积累的空间数据资产
如视长期专注于空间数字化领域。过去十余年间,基于全球 70 余个国家与地区真实场景全面采集,积累了超 5800 万的全球最大三维空间数据库 —— 精确还原物理空间布局,支持用于导航、场景理解与闭环仿真。这些数据覆盖:住宅空间、商业空间、零售空间、工业空间。这种规模和丰富度,在行业内算是“独一份”。
对于空间大模型而言,这意味着模型训练过程中能够接触到足够丰富的真实世界空间分布,从而获得更强的:空间推理能力、场景泛化能力、多源数据适应能力,这也是 Argus1.0 能够实现高精度空间重建的重要基础。
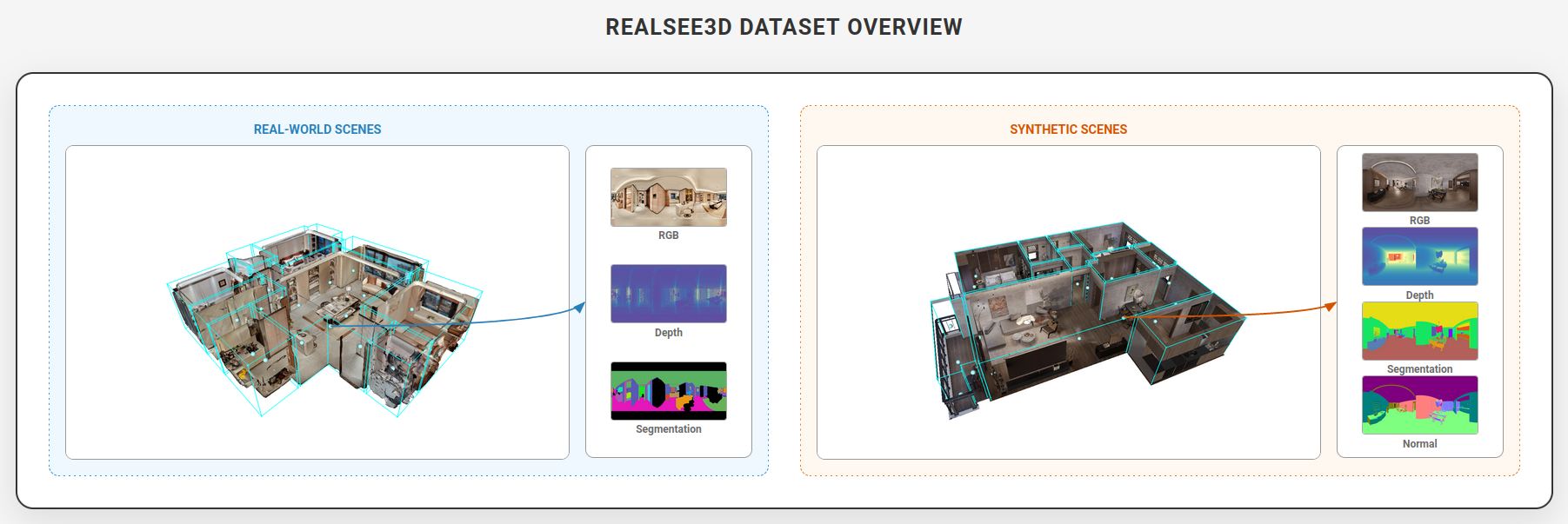
如视在数据集开源领域也硕果累累。在 2025 年底,如视重磅开源了 REALSEE 3D —— 全球目前最大的面向室内 3D 感知与重建的多视角 RGB-D 数据集,含 10,000 个室内场景,配套全景 RGB-D、CAD / 平面图、语义分割与 3D 检测标注。相较于之前较大规模的 Habitat 数据集,Realsee3D 在真实场景规模上达到其 10 倍以上。REALSEE 3D 数据集旨在推动室内三维感知、重建与场景理解领域的研究。凭借出色的质量,该数据集得到了相关从业者的广泛认可与高度评价。
REALSEE 3D 数据集下载链接:
https://github.com/realsee-developer/RealSee3D
真实场景驱动,赋能具身智能训练场
依托体量庞大、类型丰富的真实三维数据资产,如视不仅能支撑大模型训练与日常三维重建工作,还可以基于标准化实景三维资产搭建专业训练环境,深度适配当下火热的具身智能与模拟器研发需求。也就是说,物理 AI 爆发前夜,如视正在补齐真实世界训练场的关键一环。
如视的十年耕耘:技术、专利与产业落地
AI 行业经常出现一种现象:论文很多,Demo 很多,真正落地很少。如视科技的不同之处在于:它已经经历了产业验证。长期以来,如视保持高强度研发投入,年均研发投入超过 2 亿元,团队也已积累了 600 余项国内外授权专利。
- 学术方面,如视科技的科研成果近年来多次入选 CVPR、ICCV 等国际顶会。
- 硬件方面,如视已经建立起从消费级到专业级的全场景空间采集产品矩阵。如今,这些产品和技术已服务于房产、零售、工业、文旅和展馆等九大行业超过 3000+ 品牌客户。

世界模型的“GPT”时刻,已经来了吗?
当下,AI 正在完成一次关键跃迁:从读懂文字图片,到解析和重建整个物理世界。结合李飞飞对世界模型的分类不难看出,主打物理仿真的模拟器,是下一代 AI 的核心方向,而实景三维数字化就是它的地基。如视科技打造的 “扫描硬件 + 三维大模型 + 开放接口” 全链条体系,正在持续夯实这一地基。
当线下的每一个场景都能快速变成数字模型,当机器人能精准理解周遭环境与物理规则,物理 AI 的下一个黄金时代也就真正到来了。你觉得,主打真实场景的模拟器世界模型,“GPT”爆发时刻已经来了吗?


